![[レポート]Amazon Redshiftで生成AIのためのデータ戦略を構築 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]Amazon Redshiftで生成AIのためのデータ戦略を構築 #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、AWS re:Invent2024に参加していた、データ事業本部の渡部です。
本日は3日目にあったChalk Talk【ANT331 Build your data strategy for generative AI with Amazon Redshift】のレポートです。
このre:InventではRedshiftのセッションにあまり参加してこなかったので、何か気になる話が聞けることを期待して参加してみました。
セッション概要
概要
本セッションでは、Redshiftへのデータ収集と、RedshiftとAWSのAIサービスの統合についての2軸で話が展開されました。
以下がセッション概要となります。
Data warehouses are pivotal in developing generative artificial intelligence applications. Organizations can use valuable domain data from Amazon Redshift, an AI-powered cloud data warehouse, for Retrieval Augmented Generation (RAG), fine-tuning foundation models, continuous pretraining, and building models from scratch. Business users can also leverage generative AI capabilities within Amazon Redshift such as Amazon Q generative SQL to generate SQL code using natural language directly in Amazon Redshift query editor, increasing productivity and reducing time to insights. Join this chalk talk to learn how you can utilize Amazon Redshift for your generative AI applications and workloads.
データウェアハウスは、生成AIアプリケーションの開発において重要な役割を果たします。組織は、AIを活用したクラウドデータウェアハウスであるAmazon Redshiftから価値のあるドメインデータを活用して、Retrieval Augmented Generation(RAG)、基盤モデルのファインチューニング、継続的な事前学習、およびモデルのゼロからの構築に利用することができます。また、ビジネスユーザーはAmazon Redshift内の生成AI機能(Amazon Q generative SQLなど)を活用して、Amazon Redshiftクエリエディタで直接自然言語を使用してSQLコードを生成し、生産性を向上させ、インサイト獲得までの時間を短縮することができます。このチョークトークに参加して、生成AIアプリケーションやワークロードにAmazon Redshiftをどのように活用できるかを学びましょう。
スピーカー
- Debu Panda, Senior Manager, Product Management, Amazon
- Sudipta Bagchi, Sr. SPecialist Solutions Architect, Amazon Web Services
セッション内容
Redshiftデータウェアハウスをどのように活用して、ビジネスに新しい規範や新しいビジネスを生み出すのに役立つ優れた生成AIアプリケーションを構築できるかについて話すとお話がありました。

Redshiftにはあらゆる種類のデータを取り込むことができると紹介がありました。
例えばS3、ストリーミングデータ、運用データベース、外部共有データです。
それらのデータに対して、Redshiftは便利な取り込みや参照機能をサポートしております。
具体的にはS3では自動的にデータを複製できるS3 Auto Copy、S3データをそのまま参照できるRedshift Spectrum、運用データベースから自動的にデータ複製するZero-ETL、運用データベースを参照するFederated Queryなどです。
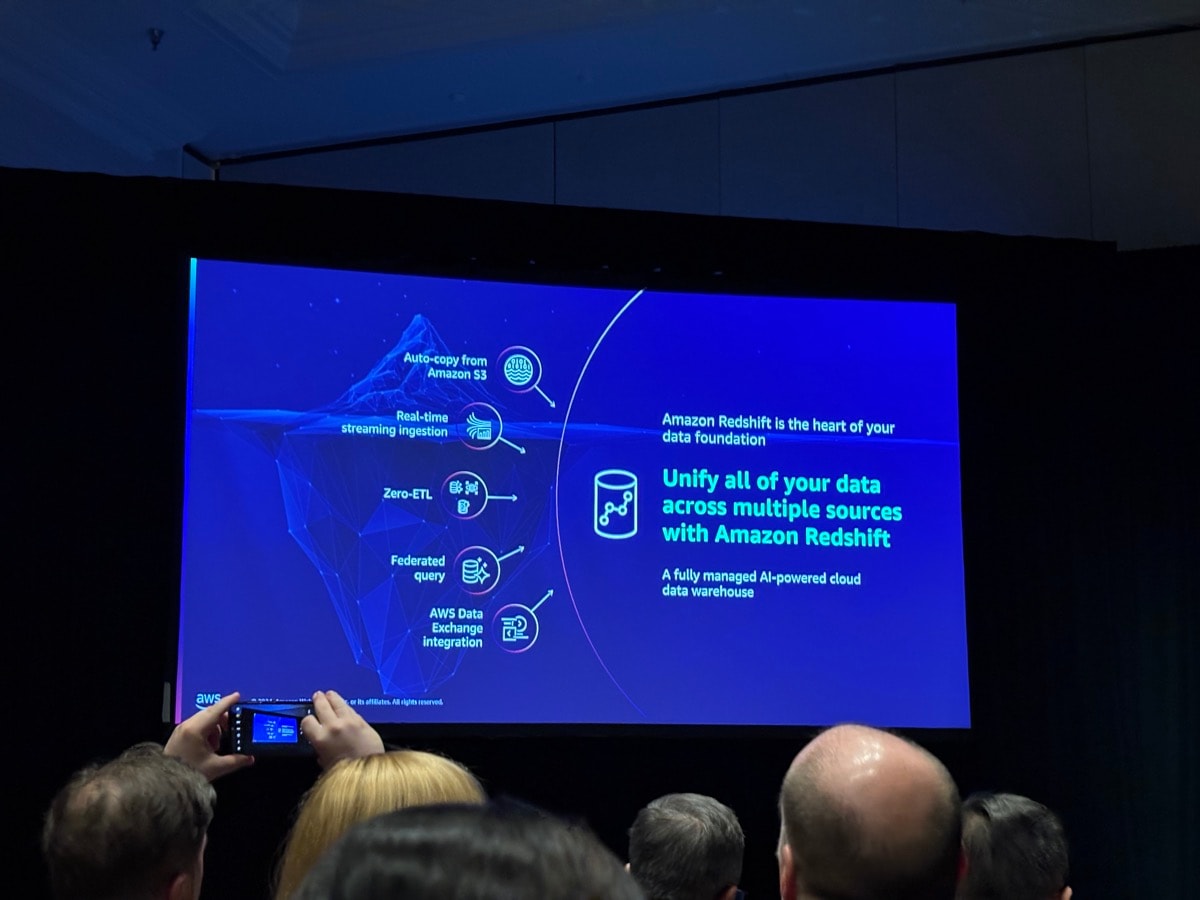
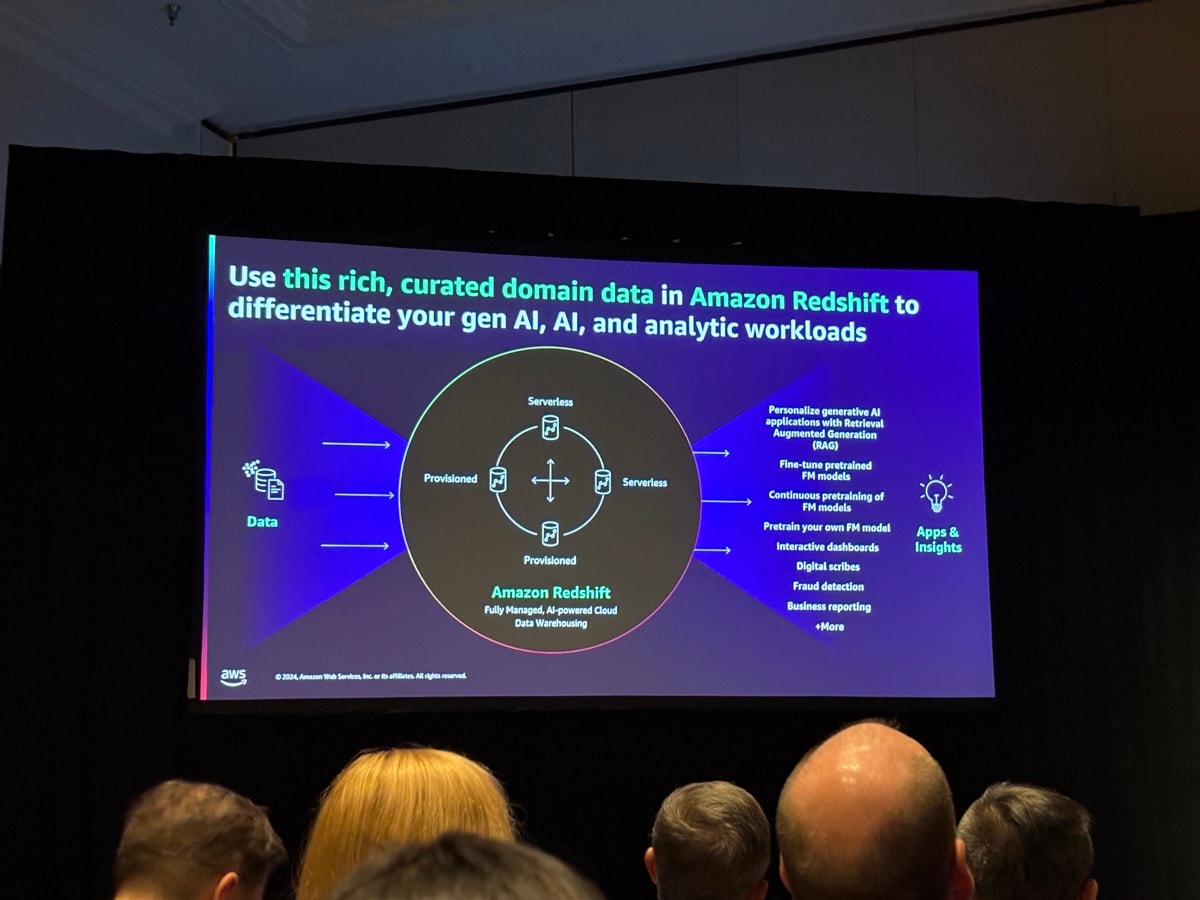
AWSのAIスタック3本柱として、Q/Bedrock/SageMakerがあると説明されました。
Qに関しては自然言語処理によるクエリ実行などのサポートがされています。
またBedrockに関しては、re:Invent2024で構造化データへのナレッジベースサポートが発表されたことに触れていました。
SageMakerに関しては、Redshift MLが紹介され、SQLクエリでモデルを作ることが可能であることが紹介されました。データサイエンティスト・機械学習の専門家でなくても、自動的にデータの前処理や、トレーニングが行われ、UDFとしてそのモデルは使用できるようになります。

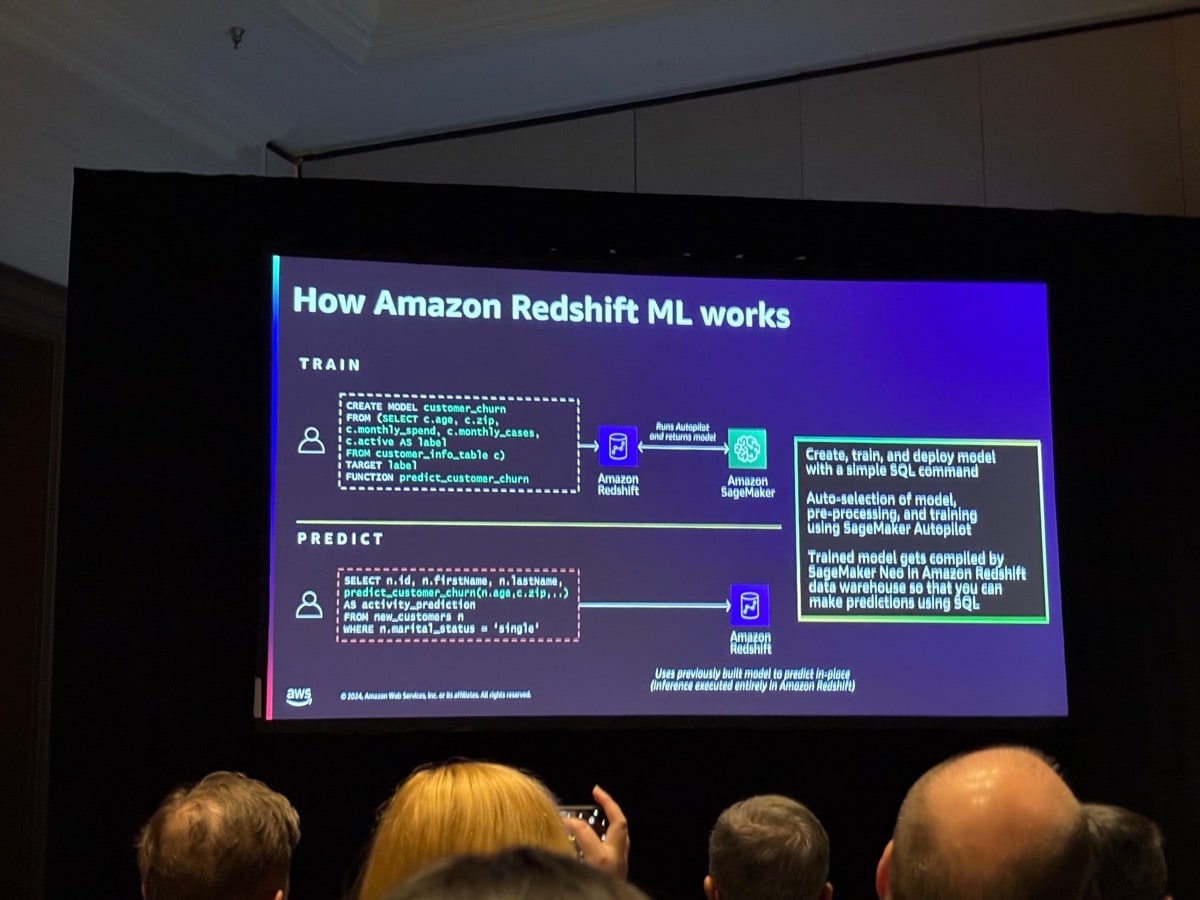
次にre:Invent2024で新発表された、データとAIを統合した新世代のAmazon SageMakerを使用したいユースケースもあるとの話になりました。

SageMaker Unified Studioではデータ・AIの統合環境として、これまでEMRやRedshift・Athenaの使用ごとにそれぞれのツールを使う必要がありましたが、それが統合環境ではシームレスにアクセスできるとのことです。
またプロジェクトという単位でプロジェクトメンバーとコード共有がすることが可能で、GitHubと連携した構成管理も可能です。
特にSageMaker Lakehouseでは、S3とRedshift、つまりデータレイクとデータウェアハウスを統合しました。
ここで嬉しいことは、例えばGlueやEMRで同じDBを使用したい場合は2つのコネクタを作成しなければなりませんでしたが、LakehouseのIceberg APIを通すことで簡単にデータアクセスが可能です。
JDBCのRedshiftエンドポイントの必要性もなくすということでした。
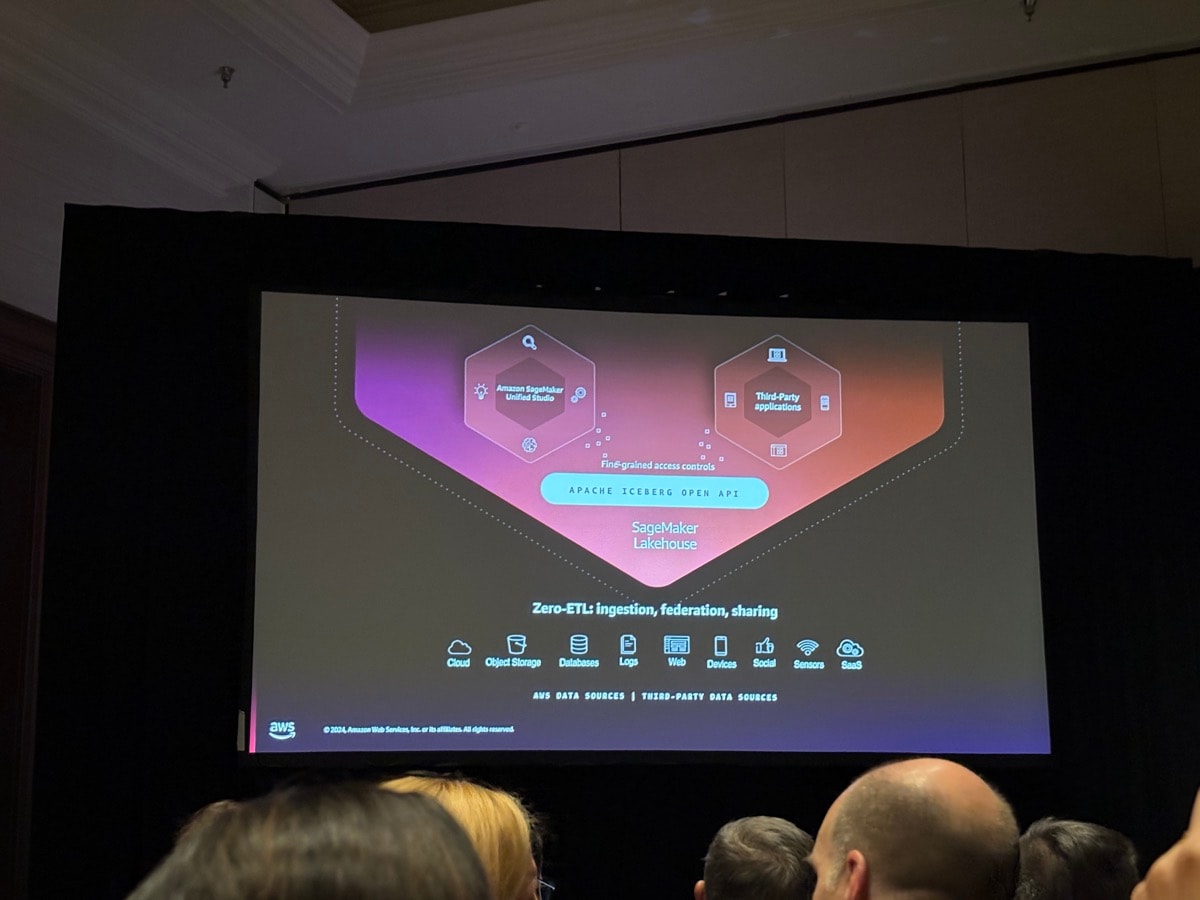
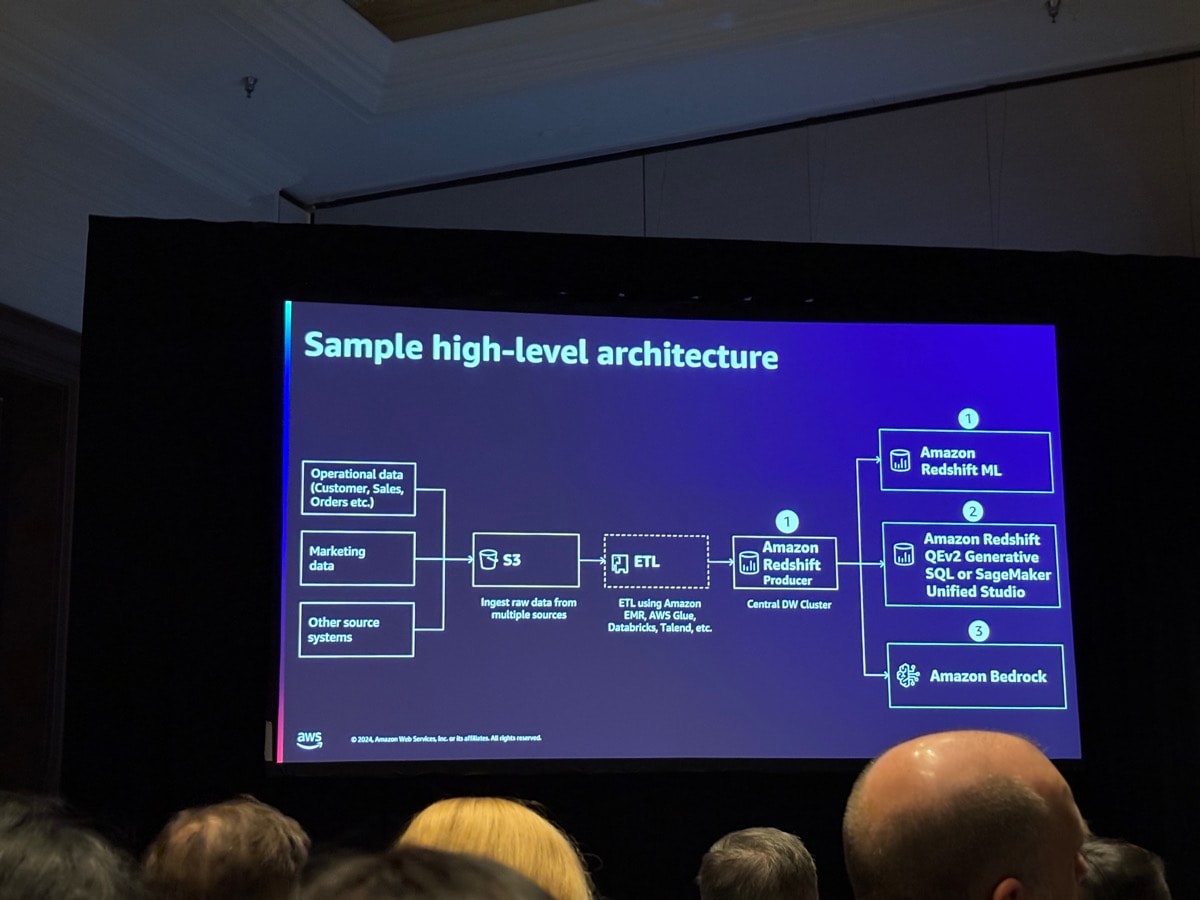
これまで説明があった内容をまとめた図が投影され、まとめとなりました。
Redshiftにさまざまなデータソースからデータが集められ、そのデータをさまざまな形で利活用をしている流れがおさえられています。
ここからは2つの企業の事例が紹介されました。
1つ目はヘルスケア企業の事例です。課題としては以下がありました。
- 患者データが複数のデータソースに分断されている
- 患者への推奨事項作成の自動化
- プログラミングのスキルは限りある
上記の課題に対して、以下で解決したとのことです。
- セットアップ可能なS3 Auto CopyやZero-ETLなど、簡単にRedshiftへデータ取り込みする機能
- Redshift ML

2番目の事例では小売企業が紹介されました。
課題としては以下2つとのこと。
- ビジネス側も分析をしたいが、毎回データチームに依頼するため迅速な分析ができないこと
- カスタマーサービスの返答が遅れること
これらの解決策としては、Qを使った自然言語でのクエリが紹介されました。
実際にデモ動画で見せていただいたのですが、「私たちのトップ10の顧客は誰ですか?」という質問に対して、自動的にクエリが生成され、データが取得できていた様子を伺えました。

さいごに
Redshiftについて今どんな機能があるのか、またRedshiftとAIサービスとの関連がおさえることができました。
特にデータ収集の観点においては、Zero-ETLやS3 Auto Copy、Federated Queryなど様々な選択肢が用意されてきました。
今一度それぞれの機能を整理して、どういう場合にどの機能を選択するのか?という観点で定義して、今後も発表される新機能と都度向き合っていくことが重要に感じられます。
以上どなたかのご参考になれば幸いです。










